I chose to use the Intel® SDK for OpenCL™ Applications, which is a free download:


I extracted the SDK from the zip file, and used the included install.exe binary to configure the SDK. I opted to allow the installer to “Setup my IDE” automatically:


This process created a directory in Program Files (x86) with the following contents:
Although Intel has a “Hello World” project sample within the samples_2020 directory, I’m choosing to instead create my own so I know how to set up a project from scratch.
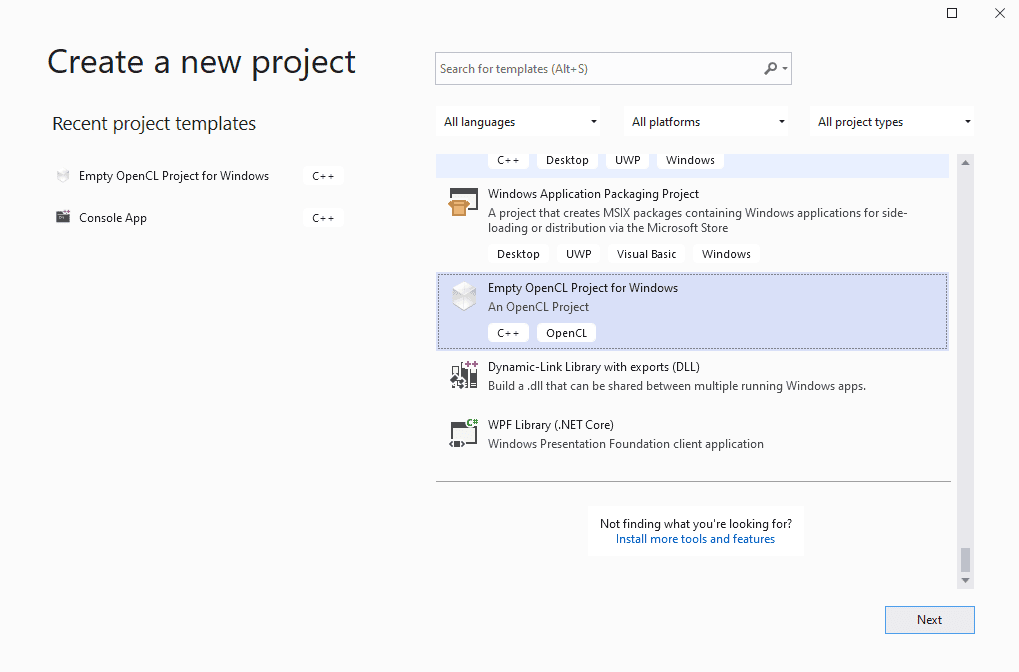
Next, create a new project in VS2019 using one of the newly added intel templates. I’m using the “Empty OpenCL Project for Windows” template:
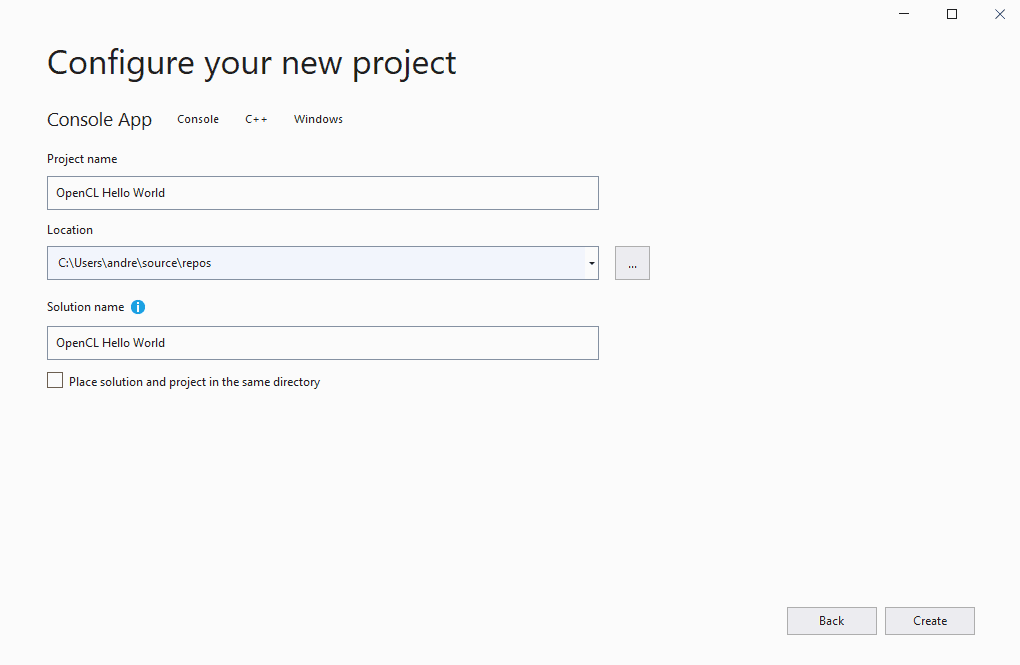
Name the project and choose a location to keep the solution, then click Create:
You’ll be given a completely clean OpenCL project, with no code for either the OpenCL device (kernel) or the host:
We’ll start by writing some basic host-side C++ code (based off of GitHub – pratikone/OpenCL-learning-VS2012):
#include <stdio.h>
#include <stdlib.h>
#ifdef __APPLE__
#include <OpenCL/opencl.h>
#else
#include <CL/cl.h>
#endif
#define MAX_SOURCE_SIZE (0x100000)
int main(void) {
// Create two lists of numbers with the same number of elements
int i;
const int LIST_SIZE = 1024;
int* A = (int*)malloc(sizeof(int) * LIST_SIZE);
int* B = (int*)malloc(sizeof(int) * LIST_SIZE);
for (i = 0; i < LIST_SIZE; i++) {
A[i] = i;
B[i] = LIST_SIZE - i;
}
// Load the kernel source code into the array source_str
FILE* fp;
char* source_str;
size_t source_size;
fp = fopen("kernel.cl", "r");
if (!fp) {
fprintf(stderr, "Failed to load kernel.\n");
exit(1);
}
source_str = (char*)malloc(MAX_SOURCE_SIZE);
source_size = fread(source_str, 1, MAX_SOURCE_SIZE, fp);
fclose(fp);
printf("kernel loaded\n");
// Get platform and device information
cl_device_id device_id = NULL;
cl_uint ret_num_devices;
cl_uint ret_num_platforms;
cl_int ret = clGetPlatformIDs(0, NULL, &ret_num_platforms);
cl_platform_id* platforms = NULL;
printf("%d Platforms Found\n", __LINE__, ret_num_platforms);
platforms = (cl_platform_id*)malloc(ret_num_platforms * sizeof(cl_platform_id));
ret = clGetPlatformIDs(ret_num_platforms, platforms, NULL);
ret = clGetDeviceIDs(platforms[0], CL_DEVICE_TYPE_ALL, 1,
&device_id, &ret_num_devices);
printf("%d Devices Found\n", __LINE__, ret_num_devices);
// Create an OpenCL context
cl_context context = clCreateContext(NULL, 1, &device_id, NULL, NULL, &ret);
// Create a command queue
cl_command_queue command_queue = clCreateCommandQueue(context, device_id, 0, &ret);
// Create memory buffers on the device for each vector
cl_mem a_mem_obj = clCreateBuffer(context, CL_MEM_READ_ONLY,
LIST_SIZE * sizeof(int), NULL, &ret);
cl_mem b_mem_obj = clCreateBuffer(context, CL_MEM_READ_ONLY,
LIST_SIZE * sizeof(int), NULL, &ret);
cl_mem c_mem_obj = clCreateBuffer(context, CL_MEM_WRITE_ONLY,
LIST_SIZE * sizeof(int), NULL, &ret);
// Copy the lists A and B to their respective memory buffers
ret = clEnqueueWriteBuffer(command_queue, a_mem_obj, CL_TRUE, 0,
LIST_SIZE * sizeof(int), A, 0, NULL, NULL);
ret = clEnqueueWriteBuffer(command_queue, b_mem_obj, CL_TRUE, 0,
LIST_SIZE * sizeof(int), B, 0, NULL, NULL);
// Create a program from the kernel source
printf("Attempting to Configure OpenCL Program\n");
cl_program program = clCreateProgramWithSource(context, 1, (const char**)&source_str, (const size_t*)&source_size, &ret);
// Build the program
ret = clBuildProgram(program, 1, &device_id, NULL, NULL, NULL);
printf("Finished Building OpenCL Program\n\n");
// Create the OpenCL kernel
printf("Attempting to Configure OpenCL Kernel\n");
cl_kernel kernel = clCreateKernel(program, "vector_add", &ret);
ret = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void*)&a_mem_obj);
ret = clSetKernelArg(kernel, 1, sizeof(cl_mem), (void*)&b_mem_obj);
ret = clSetKernelArg(kernel, 2, sizeof(cl_mem), (void*)&c_mem_obj);
printf("Finished Configuring OpenCL Kernel\n\n");
// Execute the OpenCL kernel on the list
printf("Attempting to Execute Kernel\n");
size_t global_item_size = LIST_SIZE; // Process the entire lists
size_t local_item_size = 64; // Divide work items into groups of 64
ret = clEnqueueNDRangeKernel(command_queue, kernel, 1, NULL,
&global_item_size, &local_item_size, 0, NULL, NULL);
printf("Finished Executing Kernel\n\n");
// Read the memory buffer C on the device to the local variable C
printf("Attempting to Copy Memory from Device\n");
int* C = (int*)malloc(sizeof(int) * LIST_SIZE);
ret = clEnqueueReadBuffer(command_queue, c_mem_obj, CL_TRUE, 0,
LIST_SIZE * sizeof(int), C, 0, NULL, NULL);
printf("Finished Copying Memory from Device\n\n");
// Display the result to the screen
printf("Calculation Results\n");
for (i = 0; i < LIST_SIZE; i++)
printf("%d + %d = %d\n", A[i], B[i], C[i]);
// Clean up
printf("\nStarting to Clean Up OpenCL Context and Memory\n");
ret = clFlush(command_queue);
ret = clFinish(command_queue);
ret = clReleaseKernel(kernel);
ret = clReleaseProgram(program);
ret = clReleaseMemObject(a_mem_obj);
ret = clReleaseMemObject(b_mem_obj);
ret = clReleaseMemObject(c_mem_obj);
ret = clReleaseCommandQueue(command_queue);
ret = clReleaseContext(context);
free(A);
free(B);
free(C);
printf("Done Cleaning Up\n\n");
system("pause");
return 0;
}
Next, we need a kernel. I used a sample “Vector Addition” kernel (also from GitHub – pratikone/OpenCL-learning-VS2012).
Make a new file in the project called “kernel.cl” and add the following:
__kernel void vector_add(__global const int *A, __global const int *B, __global int *C) {
// Get the index of the current element to be processed
int i = get_global_id(0);
// Do the operation
C[i] = A[i] + B[i];
}You can now use the Windows Debugger to test the code. Choose a Configuration and a Platform, the click Run:
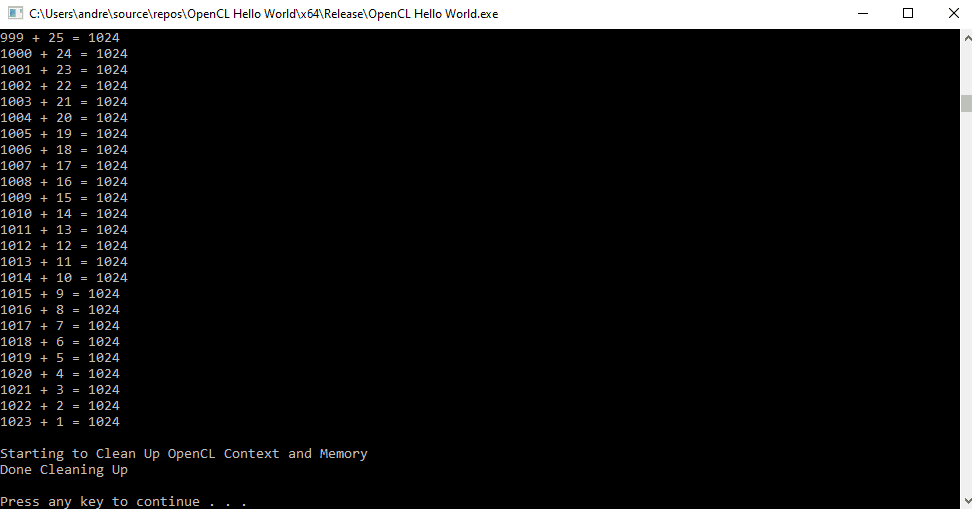
The result should be a printout of the addition of various combinations of numbers: